At bet365 we are always looking for opportunities to give back to the golang Open Source community. A recent example of this was improvements to the excellent go-mssqldb driver authored by denisenkom @ https://github.com/denisenkom/go-mssqldb.
Whilst we use Riak extensively to under pin our OLTP platform, we also have a large Microsoft SQL Server estate. Typically this has been accessed using Microsoft’s native SQL drivers via ADO.NET. As part of our technical improvement program we were looking to replace a number of existing .NET services with golang equivalents. This in turn led to the question as to how best to access Microsoft SQL databases.
We opted for the idiomatic golang approach and looked to use the standard library database/sql. This defines a common interface for database driver providers to implement and a consistent approach for consuming these drivers.
What quickly became apparent however, at the time, is that Microsoft doesn’t provide a native golang driver. Faced with writing our own driver we first looked to see what was available in the Open Source community. A quick search on GitHub revealed a number of implementations with go-mssqldb seeming the most mature.
Having evaluated it, we identified several areas where we felt the driver could benefit from some of the techniques developed within bet365 to maximise performance in high load components. The scope was extended to include performance improvements that would benefit not just our use cases, but the wider community.
Subsequently Microsoft has officially adopted this driver and included these improvements as part of the first version release candidate.
Performance evaluation approach
In order to exercise the driver we created a set of stored procedures that each exercise one SQL server datatype, int, bigint, varchar etc. The procedures are each very simple, they take a parameter of the test type and return a set of data of that type.
We can then call the procedure repeatedly while profiling using go tool pprof.
Below we can see the flamegraph of our tests when returning large amounts of varchar data. Each bar represents a single function in the code and the size of that bar indicates the relative amount of CPU time spent in each function and its children.
root is the top level, 100% of execution is under this. As we can see, the driver is spending most of its time in processSingleResponse. In turn parseRow is responsible for the vast majority of that.
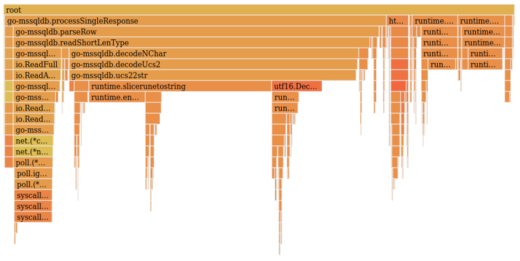
Since we are sending large amounts of varchar data this is perhaps not surprising, but we should investigate. Double clicking on a function bar will zoom into it.
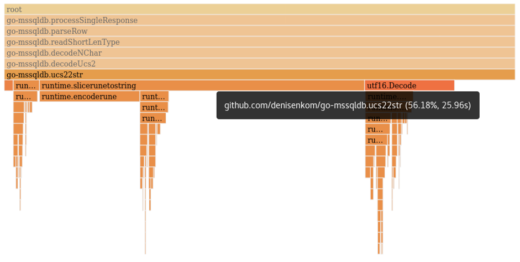
parseRow calls down through several functions, each of which take up 100% of the execution time of its parent. Eventually ucs22str appears to do real work, calling slicerunetostring and a smaller, though still significant, amount of time in utf16.Decode. ucs22str is responsible for 56.18% of our execution time.
Let’s take a look at the code for ucs22str…
func ucs22str(s []byte) (string, error) {
if len(s)%2 != 0 {
return "", fmt.Errorf("illegal UCS2 string length: %d", len(s))
}
buf := make([]uint16, len(s)/2)
for i := 0; i < len(s); i += 2 {
buf[i/2] = binary.LittleEndian.Uint16(s[i:])
}
return string(utf16.Decode(buf)), nil
}
It validates that the length of the incoming byte slice is even.
if len(s)%2 != 0 {
return "", fmt.Errorf("illegal UCS2 string length: %d", len(s))
}It allocates a new uint16 slice, of half the original length. This is actually the same number of bytes overall, it is simply transforming the bytes into uint16s.
buf := make([]uint16, len(s)/2)
It then copies 2 byte chunks into the new slice, transforming with a call to binary.LittleEndian.Uint16
for i := 0; i < len(s); i += 2 {
buf[i/2] = binary.LittleEndian.Uint16(s[i:])
}And finally it calls utf16.Decode, which returns a slice of rune.
return string(utf16.Decode(buf)), nilThe majority of the time is spent in the final line. The string(…) type conversion is compiled to slicerunetostring, which is where the majority of time is being spent. slicerunetostring transforms a slice of runes (32bit numbers) into a utf-8 string by iterating the slice and calling encoderune for each element. It also needs to do two passes through the input slice as encoderune can encode to a variable number of bytes. It therefore needs to pre-calculate the encoded length of the final string before allocation.
To be able to make this faster we must understand why it is doing these steps more clearly. What is ucs22str? It turns a byte slice into a string via some Unicode decoding. What is in the byte slice?
MS SQL Wire Protocol
The MS SQL Server wire protocol is TDS (Tabular Data Stream).
https://en.wikipedia.org/wiki/Tabular_Data_Stream
As part of the protocol, string data (varchar, nvarchar etc) is sent encoded as UCS2, which is a 16-bit per character encoding. Every character is represented by a Little Endian 2-byte Unicode code.
E.g. a LATIN CAPITAL LETTER “H” has the code 0x0048 and is stored as a 2-byte sequence 0x48 0x0 or 72, 0 in decimal e.g.
| 16bit char | H | e | l | l | o | W | o | r | l | d | ||||||||||
| bytes | 72 | 0 | 101 | 0 | 108 | 0 | 108 | 0 | 111 | 0 | 87 | 0 | 111 | 0 | 114 | 0 | 108 | 0 | 100 | 0 |
While a CYRILLIC SMALL LETTER YERU “ы” has the code 0x044B and is stored as a 2-byte sequence 0x4B 0x04 or 75, 4 in decimal as below.
| 16bit char | Ы | |
| bytes | 75 | 4 |
And in binary
“H” 72, 0
| Position | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Bit | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
“Ы” 75, 4
| Position | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Bit | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
The Approach
The majority of the data we handle at bet365 is in the ASCII set, only a small fraction requires full Unicode. If we can detect that the text as a whole is ASCII it can be converted more efficiently by simply copying all the low bytes to a new byte slice and casting to string. We wouldn’t need to make a uint16 slice, or decode utf16 or even have the compiler emit a call to slicerunetostring. While we are at it I believe we can improve the Unicode case also.
Any 16 bit chunk with < 128 in the low byte and 0 in the high byte and indicates a plain ASCII character. If that is true through the entire string then we are safe to use our new method.
Iterating On That Approach
We started by writing the simplest code that would work. It just iterates the input slice in steps of two checking that the string is ASCII with simple comparisons. If it is then it does another pass through the input and copies every odd byte to a new byte slice and casts that to string.
func ucs22str(s []byte) (string, error) {
if len(s)%2 != 0 {
return "", fmt.Errorf("Illegal UCS2 string length: %d", len(s))
}
// a pass through the array to see if we have any non ascii chars to decode from the us2 stream
useFastPath := true
for i := 0; i < len(s); i += 2 { if s[i] > 127 || s[i+1] > 0 {
useFastPath = false
break
}
}
// if we have not detected any “non-ascii” chars we can use a fast path
if useFastPath {
// convert directly to utf8 (in the form of ascii)
buf := make([]byte, len(s)/2)
for i := 0; i < len(s); i += 2 {
buf[i/2] = s[i]
}
return string(buf), nil
}
// otherwise take the original path and decode the ucs2 into runes and then into a string.
buf := make([]uint16, len(s)/2)
// pull out 16bits at a time
for i := 0; i < len(s); i += 2 {
buf[i/2] = uint16(s[i]) | uint16(s[i+1])<<8 // instead of binary.LittleEndian.Uint16(s[i:])
}
return string(utf16.Decode(buf)), nil
}Of course we need a way to determine if the new version is more performant. As well as running the original load test we can also write Benchmarks using the testing package. This is often a faster way to iterate on a small subset of functionality. We need to test with a range of input categories:
- Short, medium and long ASCII strings.
- Long strings of ASCII with a Unicode character at the end
- Strings of just Unicode characters
The two extremes are found on the short ASCII and trailing Unicode strings. They will often be the fasted and slowest input to decode.
Here we can see the comparison between the original implementation and our new one on these two input types.
| Benchmark | Executions | Speed up | ns/op | B/op | Allocs/op |
| ASCII Reference | 12,326,566 | 1 | 97.4 | 32 | 3 |
| ASCII 2 | 31,644,567 | 2.50 | 38.9 | 6 | 2 |
| TrailingUnicode Reference | 4,297,125 | 1 | 274 | 160 | 3 |
| TrailingUnicode 2 | 4,191,873 | 0.97 | 283 | 160 | 3 |
Even this simple implementation already beats the original by a factor of 2.5x on ASCII as well as using less memory. However, Trailing Unicode suffers a 3% slowdown due to the initial pass through the slice to check for non ASCII which is wasted.
We can do better however. The slowdown on Unicode and trailing Unicode can be improved on. We iterated on this quite a few times testing permutations that would make ASCII decoding faster, at the expense of Unicode and vice-versa. These experiments included implementations featuring:
- Optimistic copying to a destination slice
- Custom arena memory allocation
- Manual loop unrolling in Go
- Bit masking instead of comparisons
- AVX assembly language
These each produced useful data on how to proceed and ultimately lead to the implementation below. This takes some of the previous techniques
- optimistic copying
- manual loop unrolling
- bit masking
But leaves the others as, although they were fast, they would have been too much of a maintenance burden in the future.
Final Iteration
Our approach will be to iterate the input string and use a bit mask to find any 1 bit in the high byte or the highest bit in the low byte of a 16 bit section.
“H” – result is zero = ASCII
| Position | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Data | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mask | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Result | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
The result of the binary AND operation is zero. This 16 bit region is within the ASCII range.
“Ы” – result is non zero – NOT ASCII
| Position | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Data | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| Mask | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Result | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
The result of the binary AND operation is not zero, we have found a value that will require handling as Unicode.
The bit mask above, converted to hexadecimal and dealing with endianness, is 0xFF80 and is only 16 bits long. However we can generalise this to any length section. Using the unsafe package (https://pkg.go.dev/unsafe) we can access our byte slice as uint64s and use a 64 bit mask 0xFF80FF80FF80FF80
With input as our byte slice and the position we want to read a uint64 from in readIndex, we can extract a uint64 as follows:
ui64 := *(*uint64)(unsafe.Pointer(uintptr(unsafe.Pointer(&input[0])) + uintptr(readIndex))) This is a fairly unintuitive line of code. It effectively circumvents all compiler safety guarantees and reads 8 bytes at an arbitrary offset from where input is stored in memory. E.g.
package main
import (
"fmt"
"unsafe"
)
func main() {
input := []byte{1, 0, 2, 0, 3, 0, 4, 0}
readIndex := 0
ui64 := *(*uint64)(unsafe.Pointer(uintptr(unsafe.Pointer(&input[0])) + uintptr(readIndex)))
fmt.Println(ui64) // prints 1125912791875585
}
As we iterate through the slice we use this to read each 8 byte section of the original slice as a uint64. We must be careful stay within the bounds of the original slice! This can also be done with 32 or 16 bit reads by changing the cast.
In Go1.17 this can be replaced with a slightly safer call to unsafe.Slice :
ui64Slice := unsafe.Slice((*uint64)(unsafe.Pointer(&input[0])), len(input)/8)which would give us a reference to a new slice (of type
[]uint64) we could iterate as normal. However, the driver must keep compatibility with previous versions of Go.
We iterate through the input byte slice in chunks of 8 bytes, optimistically copying the low order bytes of each 16 bit section to a newly allocated byte slice half the length of the input.
In each iteration we mask off 8 bytes with a binary AND of our 64 bit mask 0xFF80FF80FF80FF80. If the result is zero, we continue copying. If it is non zero, we know we can’t treat the string as ASCII and must fall back to our Unicode path.
Assuming we are on the fast path, once we have processed all 8 byte chunks there may be up to 6 remaining bytes left in the input slice. The actual length remaining will be either 0, 2, 4 or 6 bytes. Depending on the actual length we handle those as two individual reads, a uint32, a uint16 or both.
Finally, the return statements should be covered. On the fast ASCII path our return statements are
return *(*string)(unsafe.Pointer(&buf)), nil This again uses the unsafe package to directly create a string from the buffer we have been copying to. This is only valid because the buf slice will not be written to again. This technique can be seen in the Go stdlib, e.g. strings.Builder
https://cs.opensource.google/go/go/+/refs/tags/go1.19.1:src/strings/builder.go;l=48
Finally we have the slow path, used when we detect non ASCII characters in the input. The original implementation copied from the input byte slice, to a newly allocated uint16 slice and passed that to utf16.Decode. However, that newly allocated slice is only read from once and is not required again after. It only exists to appease the compilers type checks, the input byte slice is already in the correct format in memory.
We can reuse the underlying memory of the input slice and create a slice of uint16 directly from it as follows. The process is essentially two stages. First declare a slice of uint16 so that the compiler can keep track of the underlying memory as we transfer & convert it. We do that via accessing the SliceHeader and assigning the Data pointer.
var uint16slice []uint16
uint16Header := (*reflect.SliceHeader)(unsafe.Pointer(&uint16slice))
sourceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&s))
uint16Header.Data = sourceHeader.Data Once a second pointer to the input data exists it is important to reference s again. This ensures that s is still in scope and will not be garbage collected. We reference s below by getting its length. When the uint16 initialisation is complete we call utf16.Decode and cast as before.
uint16Header.Len = len(s) / 2
uint16Header.Cap = uint16Header.Len
return string(utf16.Decode(uint16slice)), nil Results
Now this is all in place we can run our tests again and assess the impact it has made.
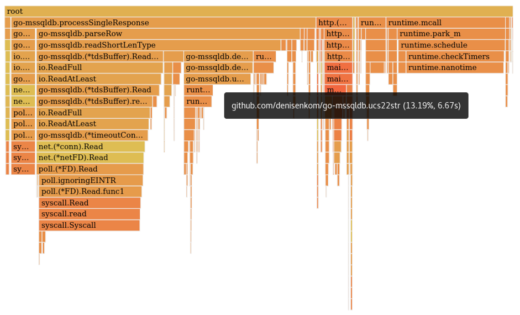
That is a good improvement! In real execution we have reduced the percentage of time spent in ucs22str from 56.18% to 13.19%, less than a quarter it’s original. Lets check the benchmarks targeting just the ucs22str function, both the original and newest version, across various inputs.
Original Implementation
| Name | Executions | Speed up | ns/op | B/op | allocs/op |
| Short ASCII | 12,274,105 | 1 | 98.6 | 32 | 3 |
| Medium ASCII | 6,721,837 | 1 | 178 | 96 | 3 |
| Long ASCII | 1,538,629 | 1 | 778 | 448 | 3 |
| Very Long ASCII | 169,466 | 1 | 7115 | 4608 | 3 |
| Trailing Unicode | 4,423,173 | 1 | 274 | 160 | 3 |
| Long Emojis | 3,166,297 | 1 | 380 | 304 | 3 |
New Implementation
| Name | Executions | Speed up | ns/op | B/op | allocs/op |
| Short ASCII | 54,690,384 | 4.50 | 21.9 | 3 | 1 |
| Medium ASCII | 35,389,251 | 5.32 | 33.4 | 16 | 1 |
| Long ASCII | 17,188,800 | 11.09 | 70.1 | 64 | 1 |
| Very Long ASCII | 2,864,568 | 16.66 | 427 | 640 | 1 |
| Trailing Unicode | 4,221,280 | 1.05 | 259 | 144 | 3 |
| Long Emojis | 3,549,286 | 1.11 | 341 | 272 | 3 |
As we can see, the each benchmark experiences a speed increase in throughput (ns/op). Overall a very nice speedup.
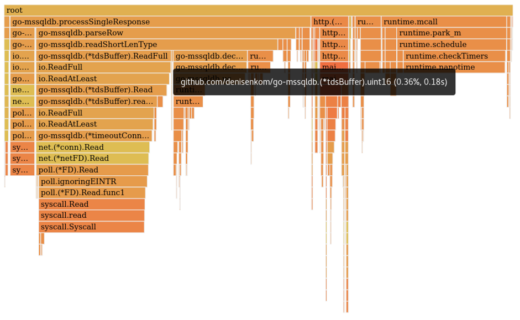
Looking again at the flamegraph we can see another candidate, albeit far less obvious.
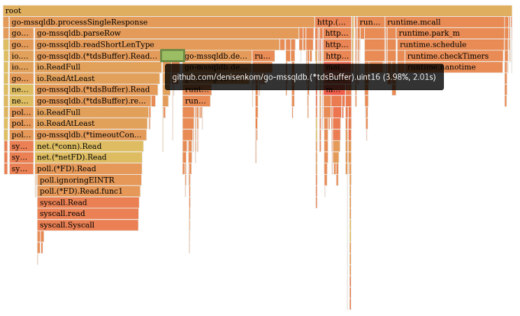
The tdsBuffer.uint16 function is used heavily in the driver, during TDS parsing, as many data lengths are expressed as 16 bit numbers. Its implementation is very straight-forward. It reads 2 bytes from the network, via the tdsBuffers own io.Reader implementation, and returns those as a uint16.
func (r *tdsBuffer) uint16() uint16 {
var buf [2]byte
r.ReadFull(buf[:])
return binary.LittleEndian.Uint16(buf[:])
}However, since the tdsBuffer is itself a buffer and holds the data read from the network in a byte slice `rbuf` field
type tdsBuffer struct {
transport io.ReadWriteCloser
...CUT...
// Read fields.
rbuf []byte
rpos int
rsize int
...CUT...
}We could save time by checking if the buffer has two bytes available to read, and using them directly. We can also build the uint16 ourselves to save the function call to binary.LittleEndian.UInt16
func (r *tdsBuffer) uint16() uint16 {
// have we got enough room in the buffer to read 2 bytes, if not, do a ReadFull, else read directly from r.rbuf
if r.rpos+1 >= r.rsize {
var buf [2]byte
r.ReadFull(buf[:])
return uint16(buf[0]) | uint16(buf[1])<<8
}
res := uint16(r.rbuf[r.rpos]) | uint16(r.rbuf[r.rpos+1])<<8
r.rpos += 2
return res
}Running the benchmarks again after uint16 is changed results in a reduction from 3.98% to 0.36%, around an 11x improvement.
We also made the same change to the uint32 and uint64 functions. These are functionally identical but operate on 32 and 64bits respectively.
| Name | Executions | Speed up | ns/op | B/op | allocs/op | Reads |
| Uint16 reference | 4,402 | 1 | 262,308 | 32,768 | 16,384 | 16,384 |
| Uint16 new | 29,956 | 6.68 | 39,227 | 0 | 0 | 16,384 |
| Uint32 reference | 7,897 | 1 | 143,915 | 32,768 | 8,192 | 8,192 |
| Uint32 new | 49,556 | 5.72 | 25,117 | 0 | 0 | 8,192 |
| Uint64 reference | 15,136 | 1 | 79,188 | 32,768 | 4,096 | 4,096 |
| Uint64 new | 89,787 | 6.04 | 13,089 | 0 | 0 | 4,096 |
The benchmark uses each function to read through a 32Kb byte buffer as one “execution”. The “Reads” column shows how many actual calls were made to the function in question. The reference implementations benefit greatly from there being no real network calls, but we still gain around a 6x improvement in call rate and have zero allocations.
Conclusion
We used the unsafe package to rewrite a UCS2 conversion function to greatly improve throughput for both ASCII and Unicode strings while decreasing allocations and overall memory usage. We also used a simple insight to improve overall TDS parsing throughput and again reduce memory use and allocations with the uint16, uint32 and uint64 functions.
Having tuned the driver, the next stage was to validate whether the expected performance gains could be realised in production with its more ‘real world’ load profiles. For this we took a simple .NET service that provided a CRUD data abstraction layer and rewrote this in golang. It was chosen as it runs a wide variety of data access patterns with varying data sizes and stored procedure execution times and therefore would expose any performance bias within the driver.
This was benchmarked and the results both in load testing and in production matched our (admittedly very high) expectations. This has resulted in being able to host this service in a significantly smaller virtual server or container footprint; obsoleting the need for the large bare metal servers previously required to host the .NET service equivalent.
During the evaluation and implementation of these performance enhancements, Microsoft officially adopted denisenkom’s go SQL implementation (https://github.com/microsoft/go-mssqldb). This has resulted in these performance enhancements being incorporated into Microsoft’s first official release candidate for this driver, along with a number of other security improvements.
We will continue to contribute to this and other open source projects as part of our open source policy and desire to work with the community to build the golang eco system.